
In-Memory Computing · 뉴로모픽 컴퓨팅 아키텍처
- 서울대 전자공학 박사
- Stanford 박사후연구
AIonEx is a fabless semiconductor company developing next-generation AI memory technologies that bring computing directly into memory — enabling real-time, on-device intelligence.
메모리 안에서 연산하는 AI. 클라우드가 아닌, 기기 그 자체에서.
지능은 아직 클라우드에 갇혀 있다
오늘날 우리가 쓰는 AI 대부분은 기기가 아니라 서버에서 연산합니다. 얼굴을 인식하고, 음성을 알아듣고, 언어를 번역하는 모든 과정에서 데이터는 일단 클라우드로 보내지고, 결과만 기기로 되돌아옵니다.
이 왕복에는 대가가 따릅니다. 통신이 끼어드는 만큼 응답은 느려지고, 데이터를 주고받고 거대한 모델을 돌리는 데 막대한 전력이 듭니다. 기존 딥러닝 기기는 추론에만도 막대한 연산량을 요구하기에, 그 무게가 곧 심각한 전력 소모로 이어집니다.
그래서 필요한 것은 명확합니다. 클라우드 없이 기기 안에서 직접 학습하고 추론하는, 저전력 온칩(on-chip) AI 반도체입니다. AIonEx는 연산을 CPU에 의존하지 않고 메모리 연산 도메인으로 흡수해, 시스템을 가볍게 만들고 전력을 극단적으로 낮추는 방향을 지향합니다. 클라우드 없이 동작하는 초저전력 personal AI가 목표입니다.
인식·번역·음성 처리가 서버를 거치며 통신 지연과 속도 저하를 낳습니다.
기존 딥러닝은 추론에만도 막대한 연산량을 요구해 전력 소모가 심각합니다.
클라우드 없이 기기 안에서 학습·추론하는 저전력 AI 반도체가 필요합니다.
CPU 기능을 연산 도메인으로 흡수해 시스템을 경량화하고 전력을 낮춥니다.
병목의 뿌리는 컴퓨터 구조 그 자체에 있습니다. 폰 노이만(Von Neumann) 구조에서 메모리와 프로세서는 분리되어 있고, 모든 연산은 둘 사이를 끊임없이 오가는 데이터 왕복 위에서 일어납니다. 데이터가 많아질수록 이 왕복이 성능과 전력의 발목을 잡습니다.
PIM(Processing-In-Memory)은 이 거리를 좁혀 온 진화의 흐름입니다. 메모리 곁에서 연산하는 Near-Memory Processing에서, 메모리 어레이 단위로 연산하는 현재의 In-Memory "Array" Processing으로 발전해 왔습니다.
AIonEx가 지향하는 궁극의 단계는 그다음입니다. 메모리 셀 하나하나가 직접 연산하는 In-Memory "Cell" Processing — 'Memory = Processor itself'. 이는 단순한 연산 가속기를 넘어 '프로세서 그 자체'를 지향하는, data-intensive 응용을 겨냥한 Non-Von Neumann 영역의 접근입니다.
메모리 곁에서 연산하던 과거·현재의 출발점입니다.
메모리 어레이 단위로 연산하는 현재의 SoTA 단계입니다.
메모리 셀 자체가 프로세서가 되는 AIonEx의 궁극 목표입니다.
생물학적 신경계에서 출발한 지능이 인공 신경망과 뉴로모픽 회로를 거쳐, 메모리 소자가 직접 연산하는 ‘기억–연산 일체형’ 반도체로 내려옵니다. AIonEx 기술이 하드웨어와 결합되는 전체 그림입니다.
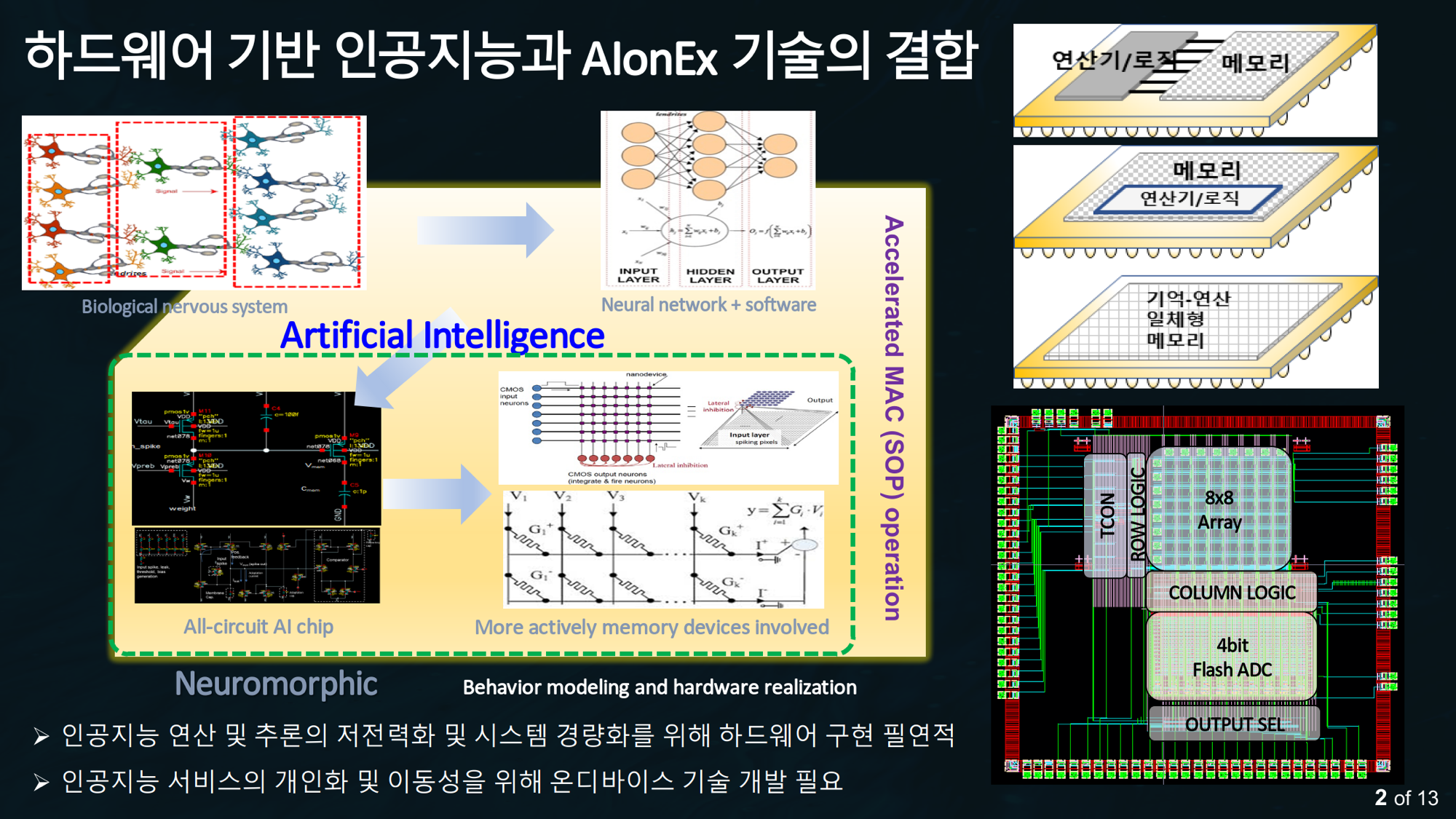
뇌에서 배운 컴퓨팅
이 방향의 영감은 인간의 뇌에서 옵니다. 뉴런과 시냅스로 연결되어 학습하는 생물학적 신경계가 인공 신경망(neural network)과 소프트웨어로 모델링되고, 다시 그것이 반도체 소자 수준의 하드웨어로 내려오는 흐름이 뉴로모픽(neuromorphic) 컴퓨팅입니다.
현재의 최신 기술(SoTA)은 신경망을 회로로 구현한 all-circuit AI 칩입니다. AIonEx가 바라보는 종착점은 그보다 한 걸음 더 나아간 곳에 있습니다.
메모리 소자가 더 적극적으로 연산에 관여해 시냅스 역할을 직접 수행하는 구조입니다. 메모리 소자가 시냅스가 되면 MAC 연산을 직접 가속할 수 있고, 신경의 거동(behavior)을 모델링한 그대로를 하드웨어로 구현하는 길이 열립니다.
뉴런·시냅스의 생물학적 신경계를 인공 신경망과 소프트웨어로 모사합니다.
현재의 최신 기술은 신경망을 회로로 구현한 all-circuit AI 칩입니다.
메모리 소자가 시냅스 역할을 맡아 MAC 연산을 직접 가속하는 구조를 지향합니다.
두 개의 트랜지스터, 하나의 연산 셀
AIonEx의 핵심은 메모리이면서 연산하는 셀을 실제 실리콘 공정으로 만들어내는 데 있습니다. 그 출발점이 단 두 개의 트랜지스터로 구성된 2T DRAM PIM 셀입니다. 완벽한 실리콘 공정 호환을 전제로 설계되어 국내외 어느 MPW로도 제작할 수 있고, PIM 셀 어레이와 주변 회로를 단일 칩으로 구현합니다.
Type-I 셀은 NMOS·PMOS 두 개의 Si MOSFET으로 구성되며 NMOS drain과 PMOS gate를 저장 노드로 씁니다. 초 단위로 향상된 retention, 우수한 endurance와 고집적, 초고속·저전력을 얻고, 읽기 전용 트랜지스터로 nondestructive read가 가능합니다.
Type-II 셀은 TR2 채널에 IGZO를 도입해 off-state current를 극단적으로 낮춥니다. data retention이 대폭 향상(10초 order 이상 예상)되어 refresh로 인한 bandwidth loss를 최소화하고, 낮은 on-state current로 전력 효율을 극대화합니다. 수직 overlapping 구조로 면적 효율을 끌어올리면서도 여전히 bulk Si 공정으로 제작 가능합니다(bulk Si TR1 + IGZO TR2 수직 결합).
그 위에 Charge Trap 시냅스 소자 기반의 온칩 학습 아키텍처를 얹습니다. 저전력 아날로그 곱셈기와 기생 성분을 줄이는 TIA(트랜스임피던스 앰프) 기반 inference 회로, 그리고 저장된 weight와 무관하게 일정 전하를 주입·제거하는 학습용 쓰기 회로(2C-4T spFG 셀 + modulated column write driver)를 통해 5비트 이상의 고해상도 weight 연산을 수행합니다.
NMOS+PMOS Si MOSFET 2개. 완벽한 실리콘 공정 호환, nondestructive read, 단일 칩 어레이+주변회로.
TR2에 IGZO 도입으로 retention 대폭 향상(10초 order↑), 수직 구조로 면적·전력 효율 극대화.
저전력 아날로그 곱셈기 + TIA 기반 inference 회로로 기기 안에서 학습과 추론을 수행.
weight와 무관하게 일정 전하 주입/제거하는 쓰기 회로로 5비트 이상 고해상도 연산.
AIonEx의 기술은 백서 위의 구상이 아닙니다. 온칩 학습과 인지 성능은 동료심사를 거친 논문과 실제 제작된 칩으로 이미 검증되었습니다. PIM Core 구조의 실측 데이터가 그 토대입니다.
핵심 성과는 IEEE Transactions on Circuits and Systems I (TCAS-I), Vol.68 No.7, 2021에 게재된 "Implementation of an On-Chip Learning Neural Network IC Using Highly Linear Charge Trap Device"로 동료심사를 거쳐 발표되었습니다.
실제 제작된 칩은 180nm CMOS 공정, 3mm×5mm die에 비휘발성 spFG 메모리를 집적하고 175MHz 시스템 클럭으로 동작합니다. 5.76Kb 온칩 메모리 위에서 결정당 학습 0.72nJ·추론 0.12nJ의 에너지로 초당 8.33M 건의 결정을 처리하며, 1비트 입력에서 5.83 ENOB의 정밀도를 보였습니다.
IEEE TCAS-I Vol.68 No.7 (2021)에 게재된 동료심사 논문으로 검증.
180nm CMOS 공정으로 실제 칩을 제작해 동작을 실측 확인.
추론만이 아니라 온칩 학습과 인지 성능까지 칩 위에서 검증 완료.
추론을 넘어, 기기 안에서 '학습'까지
전 세계적으로 메모리 기반 뉴로모픽 연구가 활발합니다. FeFET(2017), NAND Flash(2019), RRAM·NOR Flash·SRAM(2020), eDRAM·PCM(2021), MRAM(2022) — 연구의 무게는 실리콘 공정 호환과 비휘발성 메모리에 실려 왔습니다.
그러나 대부분은 칩 안에서 추론만 수행하는 오프칩 학습(off-chip learning, MAC accelerator)에 머뭅니다. 학습은 여전히 칩 밖에서 이루어집니다.
AIonEx의 차별점은 분명합니다 — 기기 안에서 직접 수행하는 온칩 '학습'입니다.
FeFET·RRAM·PCM·MRAM 등 실리콘 호환 비휘발성 메모리 연구가 활발합니다.
대부분은 칩 내 추론만 수행하는 MAC accelerator에 머뭅니다.
AIonEx는 기기 안에서 직접 학습까지 수행하는 길을 지향합니다.
검증된 기술은 검증된 사람에게서 나옵니다. AIonEx는 In-Memory 컴퓨팅, 반도체 소자, 회로·SoC를 아우르는 전문가들이 차세대 온디바이스 AI 플랫폼을 함께 개발합니다.
In-Memory Computing · 뉴로모픽 컴퓨팅 아키텍처
반도체 소자 · 2T DRAM PIM 셀 구조 설계
온칩 학습·추론 회로 · 시스템 통합(SoC)
현재 개발 중인 핵심 기술과 제품은 2026년 10월 이후 순차적으로 공개됩니다. 기술·제품의 상용화 진척에 맞추어 홈페이지도 전면 리뉴얼할 예정입니다.